

В предыдущем номере мы начали публикацию коротких этюдов о «нестандартных» гаджетах для потребления контента в целом и чтения книг в частности. Сегодняшняя история посвящена медиаплеерам.
Этот класс «недоделанных» устройств (как и фоторамка) был попыткой создать дешёвый аналог полноценному планшету. Предназначались они для пассивного просмотра медийных ресурсов (изображения и видео) и прослушивания аудио. Хотя, очевидно, текст также является медиа, никто специально просмотр текстовых файлов не включал. О возможных причинах поговорим ниже. Главным преимуществом «доделанных» устройств (планшетов, ноутбуков, смартфонов и т.п.) является тот факт, что в устройстве разделяется ядро (аппаратура и операционная система) и программное обеспечение, которое набирается в соответствии с имеющимися задачами. Есть задача смотреть видео — ставим одни программы, для чтения текстов в разных форматах дополнительно устанавливаем другие. В «недоделанных» устройствах всё грузится на заводе (к ядру добавляется комплект ПО) и называется прошивкой. Пользователь поменять прошивку не может, но вправе обратиться к поставщику (или решить проблему на тематических форумах), чтобы в прошивку включили что-то новое, внесли те или иные изменения, оптимизирующие работу устройства, и т.д…
Стоковая прошивка не предусматривала просмотра текста даже в простейшем формате (Plain text или TXT). Не знаю, в чём причина, но рискну предположить, что проблема состояла в том, что те медиа, для которых имелось ПО просмотра/прослушивания, никак не зависели от языка, и поэтому (хотя работа с этими медиа куда сложнее, чем с простым текстом) ПО для работы с изображениями, видео и аудио были в прошивках, а работу с текстом в начальные версии прошивок просто не включали. Можно было, конечно, «выкручиваться» как с фоторамкой, но хотелось большого и чистого счастья…
Немного о языках, точнее, о кодировке текста. Изначально в СССР (и в других странах мира) ввозили и адаптировали (иногда и «передирали») американские компьютеры. Текст в них кодировали с помощью 7-битной версии (она была максимально компактной, и при передаче по модемным каналам незадействованный восьмой бит использовался для контроля ошибок) ASCII-кода (American standard code for information interchange, или Американский стандартный код для информационного обмена). Семь бит позволяют закодировать 128 разных кодов. Этого вполне хватало на латиницу (даже с типовыми диакритическими символами) в режимах строчных и заглавных букв, но уже символы национальных алфавитов (греческий, кириллица и т.п.) включать было некуда. При локализации в СССР стандартным приёмом было то, что латиница существовала только в виде строчных букв, а кириллица существовала в виде заглавных букв. Скорость и надёжность информационного обмена росли, и стало возможным использовать восьмой бит не для контроля передачи, а для подключения национальных алфавитов. Первая половина 8-битного кода (коды от 0 до 127) совпадала с 7-битной кодировкой латиницы, а вторая половина (коды от 128 до 255) использовалась для кодирования текста в национальном алфавите. Первая половина кодировки у всех была общая, а вот вторая половина у каждой страны была своя. И при поставке компьютера требовалось устанавливать ПО, рассчитанное на работу с «правильным» национальным языком (нельзя поставлять в Россию текстовый редактор, который интерпретирует и отображает на экране коды из второй половины как символы греческого или грузинского алфавитов). Для устройств, главной доблестью которых является очень низкая цена, наличие «страновых» особенностей (для каждой страны должна выпускаться своя прошивка) увеличивает цену. Думаю, что именно это заставляло «забывать» включить в прошивку просмотр текстов…
Но время шло, росли объёмы памяти и быстродействие, для хранения одного символа стали выделять не один байт, а два. Такая кодировка получила название Unicode. Теперь у каждого языка была одна (или несколько) кодовых страниц. Единственной проблемой было то, что при создании устройств отображения информации (дисплеев) приходилось предусматривать отображение всех кодировок всех языков, которые были предусмотрены в Юникод. Как только это свели к одной микросхеме (чаще даже части микросхемы управления дисплеем), проблема была решена. И работа с текстами появилась в прошивках. Да, речь шла о примитивных текстах без форматирования, но и это уже было прорывом.
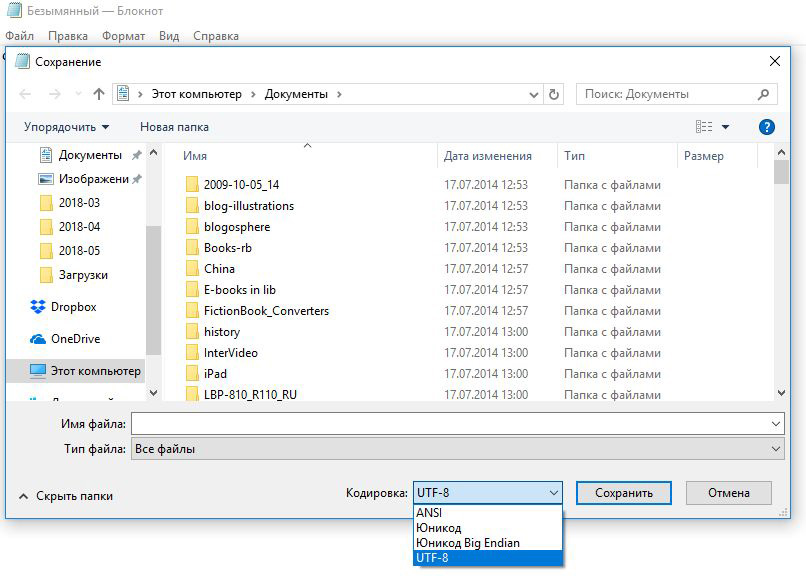
В своё время мы в РГБМ смело рекомендовали пользователям именно такое применение медиаплееров в качестве бюджетного решения для чтения текстов и гордились тем, что нашли столь простой вариант. И вдруг к нам начали приходить люди с претензиями. И рассказывают всё вроде правильно (берём текст в редакторе Блокнот, сохраняем его в единственно возможном формате TXT и переправляем в медиаплеер, а там читается нечто невообразимое). И не сразу дошло, что так текст сохраняется в однобайтном ASCII-коде, а не в двухбайтном Юникоде. А для того, чтобы текст можно было прочитать на плеере, его следовало сохранять в Юникоде — как это показано на рис. 1.
Окончание в следующем номере



Оставьте первый комментарий